
Mean Time Between Failures (MTBF) Meaning
MTBF measures the average time a mechanical or electrical system remains operational between failures (measured in hours). For example, an MTBF of 60 hours means that an asset can continue operating for 60 hours without failing. The higher the value, the more reliable the system.
MTBF is an important failure metric that indicates the effective production time between breakdowns. Performance metrics are important for any company whose operations depend on equipment. This metric originated in the aviation industry, where aircraft failure can lead to fatalities.
Why Measure MTBF?
MTBF Failures helps organizations understand the availability (AKA uptime) and reliability of their equipment. Reliability refers to the probability that a piece of equipment will perform as intended for a specific period of time, while availability expresses the percentage of time the equipment is used out of the total time being observed.
In fact, Mean Time Between Failures is one-half of the formula used to calculate availability, along with MTTR (Mean Time to Repair). An equipment’s total uptime can be expressed as MTBF together with MTTR. Together, these two metrics are used to anticipate how likely an asset is to break down within a certain time period or how often a certain type of failure may occur.
By estimating when equipment may fail, companies can prepare for contingencies that require equipment repair. Anticipating machine failure using a reliable data source improves scheduling maintenance, inventory planning, and system design. In fact, MTBF can be used in a variety of business decisions, especially where it concerns the procurement of heavy machinery and high-value assets.
Important: MTBF is only applicable to repairable items. For non-repairable systems, MTTF is an equivalent metric used to determine how long an asset can be used before its useful life is over.
MTBF Calculation
Mean Time Between Failures is generally derived over a period of time spanning multiple failures so an arithmetic mean can be calculated. Bear in mind that MTBF is not a static value. Patterns will change over time as an asset ages.
The famous bathtub curve (see below) models how the instantaneous failure rate changes over time. During an asset’s early life, failure is highly likely. Throughout most of its useful life, the failure rate remains constant, until the asset nears the end of its useful life when the likelihood of failure rises again (similar to a human body going through a normal aging process). The bathtub curve gives you a proxy for the average lifetime of an asset.
The Mean Time Between Failures formula is as follows:
MTBF = Total uptime
Number of failures
For example, an asset may have been operational for 2,000 hours in one year. But over the course of that year, it broke down six times. Therefore, the Mean Time Between Failures for that asset is 333 hours.

Avoid taking the MTBF estimate from an equipment manual at face value. Equipment performance is affected by many human factors, including handling, assembly, maintenance, usage, and more. Some examples include the quality level of the components you procured, manufacturing variability, shipping problems, customers’ misuse, etc that can affect how long an asset lasts.
Investigating certain types of failure
MTBF allows you to track patterns in the reasons why assets fail, allowing you to investigate why a certain issue is leading to a lower value. Perhaps the asset has a defective part or technicians are inadequately trained on how to service it. Good maintenance will increase the MTBF and lower overall equipment time.
MTBF vs MTTF
While Mean Time Between Failures is used to measure the failure rate of repairable items (assuming that failure occurs multiple times over the asset’s life cycle), MTTF measures how long it takes for a non-repairable item to fail—effectively yielding the asset’s total life cycle. When a non-repairable asset fails, it must be replaced.
(Remember that MTBF is an average and does not represent an asset’s life cycle.)
Consequently, MTTF only requires a single data point, seeing as once the asset fails it cannot be recovered. MTTFs apply to two types of replaceable/non-repairable items:
- Replaceable products that cannot be repaired
- Replaceable subsystem product within a repairable product
MTBF Example
To calculate MTBF, you need a few other data points.
Find the total uptime (in hours) – To find uptime, you’ll need to monitor an asset for a given period of time. Say you monitor three heavy machines for 100 hours each. Total uptime = 300 (3*100) hours.
Figure out the number of failures – Identify the number of failures over the number of assets tested. For this example, let’s say there were six failures.
Calculate MTBF – Now that we know testing was conducted for 300 hours with six failures, we can calculate MTBF.
MTBF = 50 (300/6) hours
In this example, MTBF tells you that this group of heavy machines can be expected to run for 50 hours without failing.
Note: MTBF is generally calculated over a period with multiple failures either multiple failures of a single asset or single failures of multiple assets of the same type so that the arithmetic mean can be determined.
Making Adjustments to MTBF
As assets age, they may begin to fail more often, which alters the MTBF.
For example, say a compactor that operates for 10 hours a day fails three times in one week. The first failure occurred 20 hours from the start time and took two hours to repair. The second failure happened 40 hours from the start time and took three hours to repair.
To calculate the total uptime for the MTBF equation, add 20 (initial uptime period), 18 (start of first downtime period minus end of first downtime period) and 37 (start of second downtime period minus end of downtime period).
So the calculation looks like this: 20 hours + 18 hours + 37 hour/3 breakdowns = 18.33 (55/3) hours
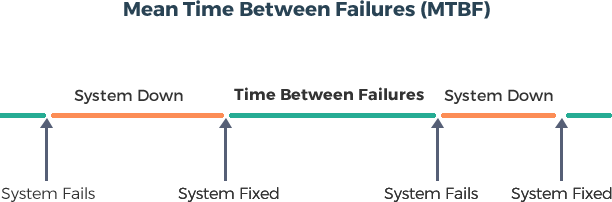
Why is MTBF Used?
MTBF enables you to predict when an asset will fail with greater accuracy. Anticipating machine failure yields myriad benefits and may even result in decreased downtime and better inventory planning.
- To be more strategic
MTBF can be deployed during the design phase of your system before manufacturing and deployment. This allows you to evaluate the expected lifetime of your assets and address any initial issues upfront. Analyzing Mean Time Between Failures can help you minimize the cost of poor quality (COPQ). - To make tough repair/replace decisions easier to rationalize
Retiring a valuable asset and buying an expensive replacement is never an easy business decision. A better understanding of an asset’s useful life can help to justify the investment (or flag an issue if the asset is breaking down too often). However, if all attempts to combat low MTBF are unsuccessful, it may be in your best interest to just replace the asset instead of continuing to spend time and money repairing it. MTBF can be used to calculate the cost of repair vs replacement and make a business case for new equipment. - To understand the reliability and availability of your assets
Component Reliability and availability are key metrics when it comes to measuring the performance of your maintenance operations and overall productivity/output relative to downtime. - To improve preventive maintenance
Increase the accuracy of your PM strategy using MTBF, which enables you to complete routine maintenance before the next failure. Enables you to calculate the frequency of inspections for preventive replacements. - To improve inventory planning
Anticipating asset failure ensures that technicians have access to tools and spare parts when they need them.
Potential Issues With MTBF
Never rely on Mean Time Between Failures as your number-one reliability metric. The problem is that it’s just a single data point, whereas breakdowns occur on a timeline. Tracking failure metrics becomes more complex as assets age and breakdowns occur more frequently. Problems after an initial repair can distort MTBF by registering as many smaller downtime instances over a shorter period.
MTBF does not remain constant and does not account for contingencies as the asset ages. Also, it is typically used to assess groups of similar or identical assets, when in reality, even identical assets from the same equipment manufacturer can perform differently due to variables outside of the maintenance team’s control (eg: quality of the parts, presence of human error, manufacturing defects, etc.). Therefore, MTBF reliability is variable

How to Improve MTBF
The goal of measuring the MTBF is to adjust your maintenance strategy in order to increase the value as much as possible. In fact, this metric shows whether or not your maintenance strategy is effective.
A higher value means that machines can remain operational for longer periods without falling, whereas a low value indicates frequent breakdowns.
1. Improve PM processes
A low MTBF could mean that maintenance interventions aren’t being done frequently enough. If you’re repairing parts or inspecting equipment after it breaks down, that drives down your MTBF. Naturally, a low MTBF necessitates more frequent preventive maintenance. Try following a stricter regimen and see if it goes up in response. Besides looking at the frequency of PM ( the most important factor but not the only one) take a close look at how PM is executed. Poor training, unclear manuals, missing inventory, and checklists can all lead to frequent breakdowns.
2. Use quality replacement parts
One likely reason for frequent breakdowns is you’re using cheap replacement parts. The system is only as strong as its weakest link.
3. Conduct a root cause analysis
Figuring out why something failed helps you prevent that failure from recurring in the future, or at least keep it from happening as often. For example, if you notice a specific part fails fairly frequently, you can replace it with a more high-quality part and increase operational efficiency.
4. Establish condition-based maintenance
Condition-based maintenance is a proactive maintenance strategy that involves monitoring the condition of an asset in real-time to determine what maintenance needs to be done. CBM is performed only when certain indicators show signs of decreasing performance. If you can establish an early warning system to detect equipment issues before they lead to failure, you can potentially increase MTBF.
How a CMMS Can Help With MTBF
A CMMS lets you keep a maintenance log, which charts each instance of maintenance for an individual asset. A CMMS systematically tracks the unplanned downtime associated with breakdowns to calculate MTBF. A performance management system gathers comprehensive information on breakdowns, including root cause analysis, countermeasures, corrective actions, and preventive actions. Supports detailed failure mode capture with issue codes and failure codes.
Maintenance software will record the date and time when a piece of equipment is reported as inactive for repair purposes. The software calculates the time taken to repair the asset until it returns to normal operating condition, which gives rise to a metric called MTTR. You can only calculate MTBF by collecting data over time, hence why a CMMS is essential for this purpose.